Accelerate Your Organic Business Growth
What We Do
L&F CG
Lorem ipsum dolor sit amet, consectetur adipiscing elit, sed do eiusmod tempor incididunt ut labore et dolore magna aliqua.
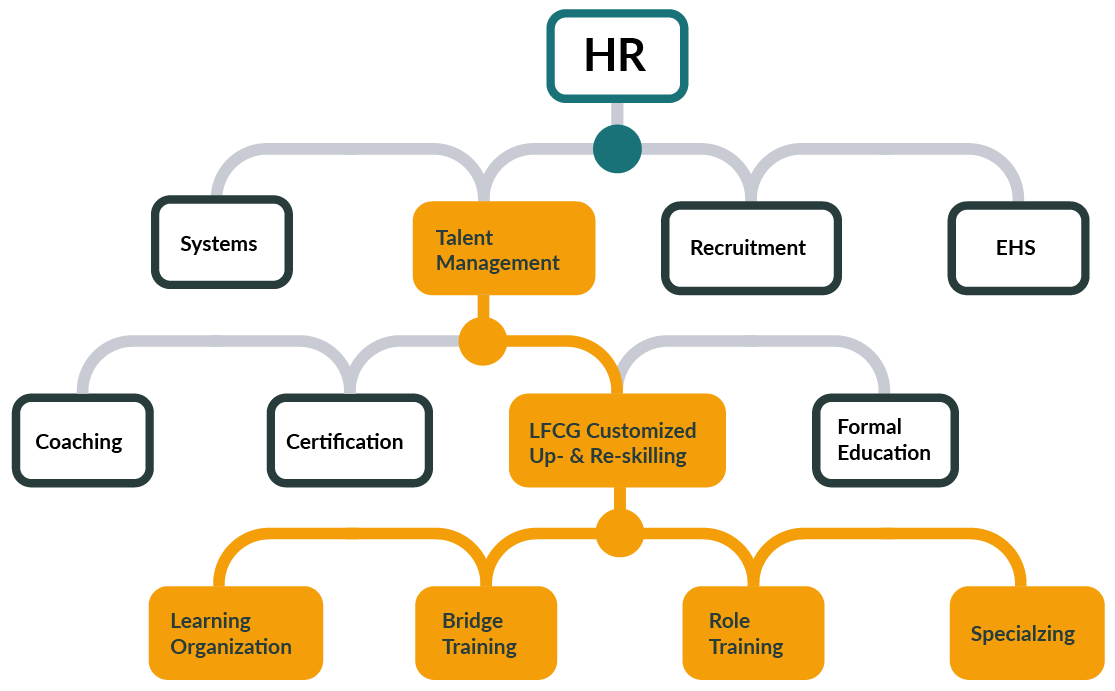
Learning Organization
A learning organization consistently endeavors to excel, continually evolving and improving. In contrast, a non-learning organization, stagnant in its ways, will ultimately fail to achieve and sustain excellence over time.
Bridge Training - Bridging
Bridging involves ensuring that your employees are equipped with the necessary skills to effectively perform to achieve the outcomes you have planned for in your budget.
Role Training - Team Player
Being a team player means ensuring your employees are fully capable and excel in their respective roles within your team and the broader organization.
Specializing - Specialist
It's about strategically focusing on honing the expertise of individuals who have the potential to become specialists in specific segments, customer groups, types, or other key variables, thereby ensuring that your company and organization successfully attain the growth targets you've set.
What We Do
L&F CG
Lorem ipsum dolor sit amet, consectetur adipiscing elit, sed do eiusmod tempor incididunt ut labore et dolore magna aliqua.
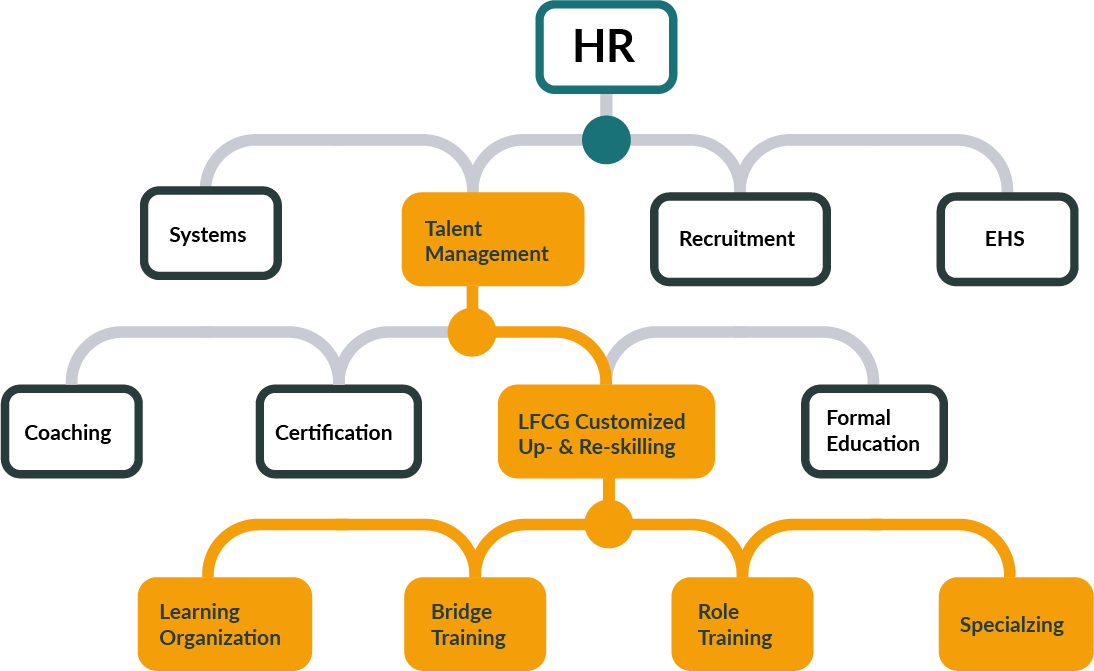
Learning Organization
A learning organization consistently endeavors to excel, continually evolving and improving. In contrast, a non-learning organization, stagnant in its ways, will ultimately fail to achieve and sustain excellence over time.
Bridge Training - Bridging
Bridging involves ensuring that your employees are equipped with the necessary skills to effectively perform to achieve the outcomes you have planned for in your budget.
Role Training - Team Player
Being a team player means ensuring your employees are fully capable and excel in their respective roles within your team and the broader organization.
Specializing - Specialist
It's about strategically focusing on honing the expertise of individuals who have the potential to become specialists in specific segments, customer groups, types, or other key variables, thereby ensuring that your company and organization successfully attain the growth targets you've set.
Laetst Insights from L&F CG
Discover fresh perspectives and innovative strategies with our latest insights and blog posts. Stay informed with our expert analyses and engaging content, tailored to keep you ahead.






Laetst Research from L&F CG
Discover fresh perspectives and innovative strategies with our latest research. Stay informed with our expert analyses and engaging content, tailored to keep you ahead.






Corporate Consulting
Management
Lorem ipsum dolor sit amet, consectetur adipiscing elit, sed do eiusmod tempor incididunt ut labore et dolore magna aliqua.
Management Consulting
Accent Heading
We have the necessary training and development facilities for roles, processes, routines and activities. We can provide the necessary recruitment and onboarding processes. We can do market and competitor analysis and assessments. We can do internal resource assessments. We can develop the necessary strategies. And we can assist and support the management team.

Resource Management
Accent Heading
Making the most of the resources at your disposal is a prerequisite to succeed as a principal in a real estate agency.
Manage your employees in such a way they reach their full potential. Manage a successful recruitment and onboarding process for future talent. Manage leads, prospects, buyers, sellers and stakeholders.
Managing partners, vendors and suppliers. Manage and develop a competitive technology stack. And manage your agency’s renomme.

Information Management
Accent Heading
“Information is power and power is money.” It is a famous quote from an unknown source.
While your resources are a known variabel. There are other variables who will affect the probability of your agency’s success. The needs and wants from your market and what your competitor do to meet those needs and wants. For you to develop a a doable growth strategy, a smart marketing plan and probable sales budget without the latter information, is difficult.

Management and Administration
Accent Heading
A strategy must be broken down into recipes. Recipes for every role, routine, process and activity. Done right, this game plan is the first step on the way to the agency’s goals. This is the administrative part of management.
The leadership part of management is to make changes when needed and to make sure the ship steer towards the port the ship set out for. Or in other word an agency’s short and long term goals.

Strategy development
Accent Heading
How to grow and outsmart your competitors by maximizing the output from your resources and marketing. Sett short and long term goals and and explain how you can reach these goals utilizing and developing your resources to meet your markets needs and wants. And explain how you will outsmart your competitors.

The LFCG Process
The Customized Upskilling and Reskilling Process
Alignment with Organizational Goals
The first step involves collaborating with management to align the upskilling and reskilling initiatives with the broader organizational objectives.
Individual Problem Assessment
Next, we engage in a thorough understanding of the individual candidate's challenges and learning needs.
Customized Training Development
We then design and implement a tailored training program for the candidate, ensuring that it delivers prompt and effective results.
Team Problem Clarification and Goal Setting
The fourth step is to work with the team to clarify any issues and establish common objectives, fostering a cohesive learning environment.
Team Reflection and Experience Evaluation
Lastly, we conduct a session with the entire team to reflect on individual and collective progress, using these insights to fine-tune goals and training approaches for continued development.